


Kaggle Competition – Modelling of claims costs and a deep dive into the winning solution
‘Earlier this year, the Actuaries Institute, Institute and Faculty of Actuaries and the Singapore Actuarial Society hosted a competition on Kaggle to promote development of data analytics talent, especially amongst actuaries. This article discusses the winning solution for the competition. In particular, how the winner derived features, built and evaluated the model which led to the best performance.
Background and purpose
For decades, the task of predicting claims costs, particularly in the general insurance industry, has been dominated by the use of Generalised Linear Models. But recently, with machine learning (ML) becoming more accessible and more data being available, non-traditional methods are starting to gain a foothold.
Earlier this year, the Actuaries Institute, the UK’s Institute and Faculty of Actuaries and the Singapore Actuarial Society hosted a competition on Kaggle to promote development of data analytics talent, especially amongst actuaries. The competition required participants to predict workers compensation claims costs using a highly realistic synthetic dataset. The winner of the competition was judged using the Mean Square Error (MSE) metric between the predicted and actual claims costs.
Data
The data comprised 90,000 workers compensation claims. For the competition, the data had a train/test split of 60/40, meaning that 60% of the total claims had total claim cost supplied and would be used to train the ML models, and 40% would not have claim cost provided; competitors would predict on the variables in the test set and competitors ranked according to how accurately they predicted the unseen claim cost.
A data dictionary for the available fields is provided below. The target variable is ‘UltimateIncurredClaimCost’. All other variables are available to use as features for prediction.
- ‘ClaimNumber’ – Unique policy identifier.
- ‘DateTimeOfAccident’ – Date and time of accident.
- ‘DateReported’ – Date that accident was reported.
- ‘Age’ – Age of worker.
- ‘Gender’ – Gender of worker.
- ‘MaritalStatus’ – Martial status of worker. (M)arried, (S)ingle, (U)nknown.
- ‘DependentChildren’ – The number of dependent children.
- ‘DependentsOther’ – The number of dependants excluding children.
- ‘WeeklyWages’ – Total weekly wage.
- ‘PartTimeFullTime’ – Binary (P) or (F).
- ‘HoursWorkedPerWeek’ – Total hours worked per week.
- ‘DaysWorkedPerWeek’ – Number of days worked per week.
- ‘ClaimDescription’ – Free text description of the claim.
- ‘InitialIncurredClaimCost’ – Initial estimate by the insurer of the claim cost.
- ‘UltimateIncurredClaimCost’ – Total claims payments by the insurance company. This is the field you are asked to predict in the test set.
We are grateful to Colin Priest for building and supplying the dataset – having access to a realistic dataset including free text allows an interesting and relevant challenge.
Feature engineering
In the context of ML, feature engineering refers to the process of using domain knowledge to select and transform the most relevant variables from raw data.
The derived features proved to greatly assist with model performance and explanation.
Some of the key feature engineering steps performed by the winning solution are summarised below.
Natural language processing on claims description
Intuitively, the free text description of the claim should provide some insight into ultimate cost. Below are some examples of the free-text claims descriptions in the raw data:
- “Tripped over cut grinder laceration right middle finger”.
- “Cutting metal foreign body left knee strain”.
- “Standing twisted knee strain”.
- “Hose burnt oil in kitchen right shoulder strain”.
- “Motor vehicle accident single vehicle neck and left foot”.
Free-text is one form of unstructured data. There are a lot of information within these texts, including the injured body part, how it was injured, position of the body part (e.g. left vs. right, high vs. low), multiple body parts (e.g. neck and left foot in the last bullet), which makes information extraction difficult.
Despite its rigor, the winning solution performed several natural language processing techniques to identify the information above. This included targeted string searches to identify the position of the injury, and identifying whether a word is a verb or a noun to separate out cause of injury from the body parts. Those interested are welcome to view the code for this procedure which is provided at the end of this article.
Transformation of the target variable
The target variable of ultimate claims costs was log-transformed as its distribution is skewed to the right. In addition, also to allow for skewness, the one outlier claim with $4m cost was scaled down to $1m. An empirical bias correction factor was used when converting the log-prediction back to the predicted dollar value.
Modelling
Using the supplied and derived features, the winning solution adopted a model stacking technique combining two base models, a lightGBM and a XGBoost model respectively.
lightGBM and XGBoost are both tree-based models using the Boosting algorithms. Hear from our very own Young Data Analytics Working Group member Zeming Yu in this video, where he will go through some lightGBM code snippets based on the Kaggle competition ‘Porto Seguro’s Safe Driver Prediction’ and discuss how lightGBM can be used to solve business problems.
‘Stacking’ is a popular technique for squeezing extra model performance needed to win Kaggle competitions. In simple terms, it allows other models to compensate for poor predictions in an existing model. The combined model is therefore stronger than the individual components. It’s common to see stacking of five or more models in Kaggle competitions. This article provides a comprehensive explanation for ‘stacking’.
The stacked model was then iterated over a number of possible combinations of weights for each model (i.e. a greedy search), during which it was found that the lightGBM model had better predictive power compared to XGBoost. The final stacked model had a weight of 85% and 15% for the two models respectively.
Key observations
Boosted tree models allow us to see how important different features are in making predictions across the dataset. Based on the modelling, and as shown in the feature importance charts below for the two models, the following features had the best predictive powers for the ultimate claims costs:
Body parts and cause of injury
Injured body parts extracted from the free-text claims descriptions seemed to inform ultimate claims costs. This is sensible as some body parts are more vulnerable to others (e.g. injury to the head versus thumb).
Similarly cause of injury was important and refers to how the body parts were injured (e.g. burn versus cut).
Claim number
An interesting observation was that the numeric part of the claim number (e.g. WC3485403) was predictive of claims costs. At first glance, this seemed odd, since it is an identifier rather than having innate information about a claim. However, it can be inferred that the number increases in line with time (i.e. claim numbers were set up in a chronological order. That is, this feature was implicitly an indicator for claims inflation, which is a sensible driver for claims costs.
Initial claims costs estimate
The initial estimate of claims costs, probably by claims assessors, was unsurprisingly an indicator for ultimate claims costs.
Wage information
Wage information such as daily and hourly wages were given feature importance. This is sensible as this is directly related to the coverage of the claim. For similar reasons, age was identified as a driver for claims costs.
Time of accident
It was interesting that the day of the accident within the month (indices of 1 – 31) was on the list. I cannot think of a qualitative explanation for this to be a claims costs driver, anyone working in the General Insurance industry is welcome to chime in here.
Chart 1: Feature importance plot – top features for the lightGBM model:
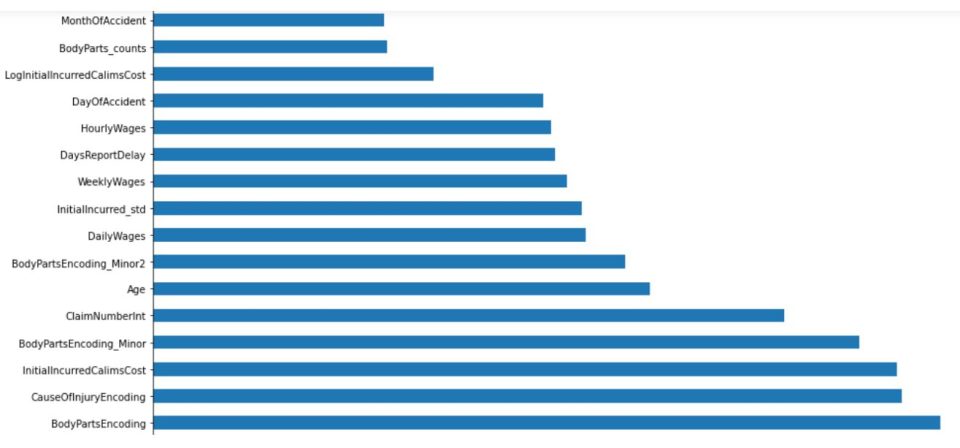
Chart 2: Feature importance plot – top features for the XGBoost model:

Winner
The winner is a Senior Data Scientist working at PRISM, the biggest insurance risk sharing pool for public entities in California. Working closely with their actuarial and data analytics teams, she develops predictive models to enhance actuarial reserving, ratemaking, and other related business problems. She also performs research for improving existing actuarial models with new statistical methods.
Below is the link to articles published by the winner on Medium:
The Juypter Notebook for the winning solution can be viewed on GitHub.
CPD: Actuaries Institute Members can claim two CPD points for every hour of reading articles on Actuaries Digital.




