


Using AI to enable fast and accurate claims data management
The critical illness insurance industry in China has witnessed significant growth over the past several years, resulting in the accumulation of millions of critical illness claims.
To address the analysis of these claims and facilitate more reliable experience studies, a standardised cause of claim database is crucial. Such a database enables actuaries to identify emerging trends early on and establish robust assumptions for critical illness pricing, valuation, product development, and innovation. To address the need for efficient claims text analysis and processing, Swiss Re has developed an AI-enabled tool, called ATOM (AuTOmated Mapping of Cause of Claims).
ATOM automates the cleaning of large volumes of claims texts and generates structured, standardised claim databases that can accommodate various critical illness claim data sets from different insurers. This capability can also be readily extended from critical illness to medical claim datasets.
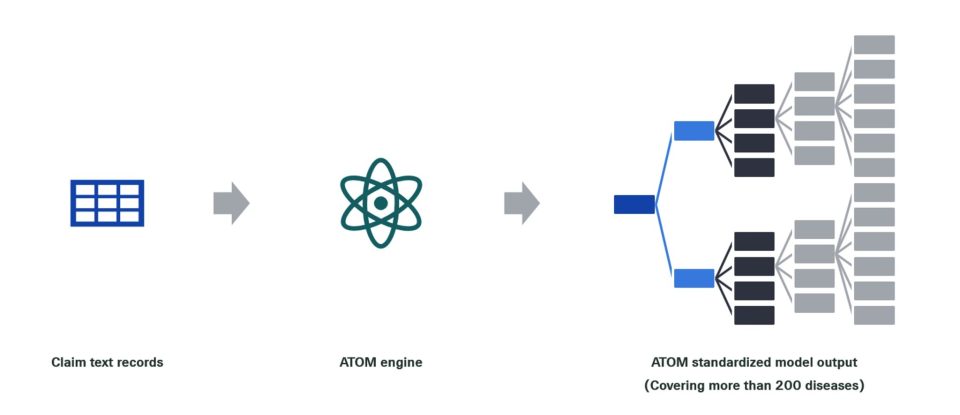
Figure 1: ATOM’s workflow.
Critical illness claims often contain essential information in the form of free text. To conduct an in-depth analysis of these claims, it is necessary to map the free text records to standardised diseases and cancer sites, following a consistent hierarchical structure and unified standard. In the past, this process was performed manually. In the case of a small sample size, this method is fast, simple, and easy to operate. However, with the rapid and continuous accumulation of claims data, the limitations of manual cleaning have become evident.
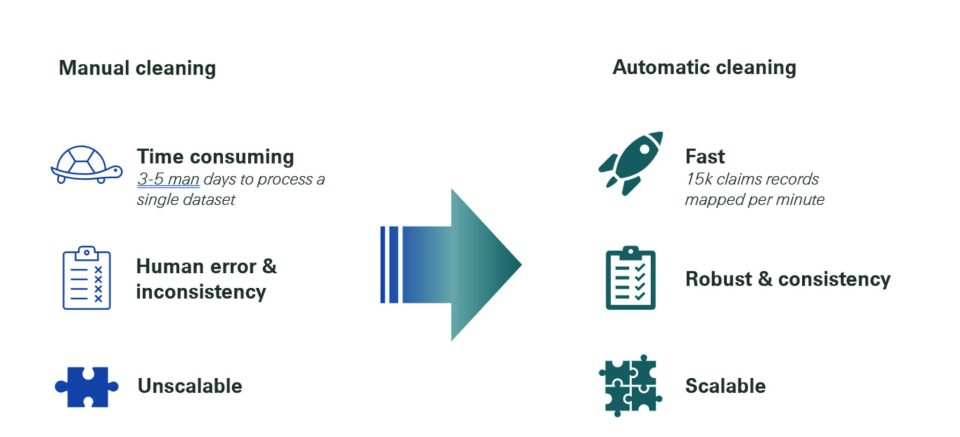
Figure 2: Comparison between manual cleaning and automatic cleaning.
The following is a brief walkthrough of the models and methods that ATOM incorporates:
- Basic – Rule-based Cleaning
This method employs regular expressions, a widely-used algorithm in traditional computer linguistics. Its aim is to use special character rules to describe and match the strings that need to be matched in a given text.
The method is simple, fast, and easily adjustable. It proves highly effective and accurate for short text cleaning and provides a rapid and efficient starting point for iterations when dealing with complex long texts.
- Intermediate – Statistical Models
Traditional machine learning text mining algorithms first convert text into a collection of sentences. Then, they apply probabilistic models such as Hidden Markov Models (HMM) to transform each sentence into a set of segmented phrases. This process refines the text into a collection of phrases composed of various key phrases. Based on this collection, statistical methods are applied to convert the text into a vector representation that can be recognized by computers. This vector representation is then used in our specific business scenarios.
The advantage of this method for describing text is its speed and directness. It transforms words and texts into mathematical representations in a simple and straightforward manner. However, it has certain limitations:
-
- When we do text-to-vector conversion, each word segmentation phrase is converted into a vector representation. However, this method does not truly capture the semantics of each segmented phrase, and the information of the surrounding words is not reflected within.
- At the algorithm implementation level, a text representation given in this way is a very large matrix with a lot of zeros, which leads to relatively slow computation.
- Advanced – Deep Learning
Deep learning introduces methods such as Word Embedding and Attention Mechanisms, which have greatly addressed the problems associated with purely using traditional statistical models.
Word Embedding: Through models like word2vec, we can establish relationships between keywords and their surrounding words. Compared to the bag-of-words model, this type of word vector representation is no longer sparse and carries certain semantic information.
Attention Mechanism: Due to the sequential nature of text input, traditional machine learning methods or recurrent neural network models cannot “remember” historical information. As shown in Figure 3 on the right, the attention mechanism effectively considers the influence of past information on the current information, thus solving the aforementioned problems effectively.
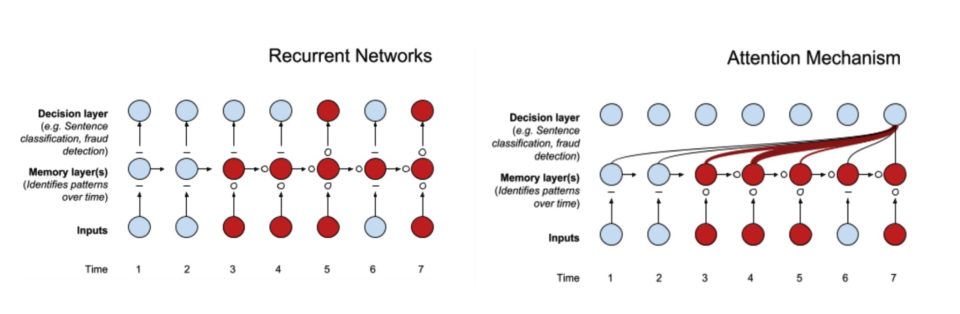
Figure 3: Comparison of Recurrent Networks and Attention Mechanism
ATOM integrates the above rule-based cleaning,modern natural language processing methods, and deep learning models. The benefits are three-fold:
- Model efficiency: ATOM significantly reduces the dependence on manual labelling and the time required for professionals in model training.
- Model application: It can be applied to different claim texts, yielding standardised claim text classification information.
- Model output: The fused model solution achieves accuracy on par with manual cleaning by experts.
With the assistance of AI, the cleaning of free text, unstructured claim causes can be accelerated from several person-days to 15,000 claims records per minute for both critical illness and medical claims. These standardised claim datasets then allow traditional experience analysis to be significantly enhanced, enabling early detection of potential trends by claim cause and providing insights for product development and innovation in the insurance industry.
CPD: Actuaries Institute Members can claim two CPD points for every hour of reading articles on Actuaries Digital.




